

Google News is a powerful news aggregator that collects and organizes news articles from various news sources worldwide. You can browse articles directly on the Google News web page or access specific categories, like business, technology, or sports, based on your interests.
This is a Google News scraper that lets you extract headlines, summaries, sources, and publication dates from Google News search results using automated scripts.
Built for developers, data teams, and businesses, it’s ideal for scraping Google News at scale for media monitoring, market research, and trend analysis.
- Rotating proxy support. Utilizes proxy rotation to prevent IP blocking and maintain uninterrupted access to Google News.
- Extract headlines, summaries, sources, and publication dates. Gathers essential article details for comprehensive news data analysis.
- Parse HTML content using Beautiful Soup. Employs BeautifulSoup to navigate and extract structured data from Google News pages.
- Automate data collection with Python scripts:. Uses Python for scripting automated news data extraction processes.
Before you start scraping, let’s make sure you have the right tools for the job. In this case, your essentials are Python and a few powerful libraries that will help you dig through the data with ease:
- Install Python. Make sure that you have the latest Python version should be installed on your machine. You can get it from the official downloads page.
- Install the required libraries. Requests and Beautiful Soup are the usual staples when it comes to scraping and parsing websites:
pip install requests beautifulsoup4
- Install Playwright. Run the following command to get the Playwright library in your Python environment. It allows you to use Playwright’s Python API to interact with browsers:
pip install playwright
- Install the necessary browsers. Get the necessary browser binaries (Chromium, Firefox, and WebKit) that Playwright uses to automate browsers. Playwright needs these binaries to run browser automation tasks, but they're not included with the initial library installation:
python -m playwright install
- Get proxy authentication details. You'll need a username, password, and endpoint information that can be found on the Decodo dashboard.
- Run the script file. Run the
google-news-scraper.pyfile with the following command:
python path/to/your/file/google-news-scraper.py
Here's the breakdown of what the code does:
- Loads the Google News website.
- Clicks the "Accept all" button to accept cookies.
- Finds the URL of the article by its class name.
- Finds the title of the article by its class name.
- Adds a counter from 0 to count mentions of specified phrases and links scraped.
- Iterates over the URLs and access each website.
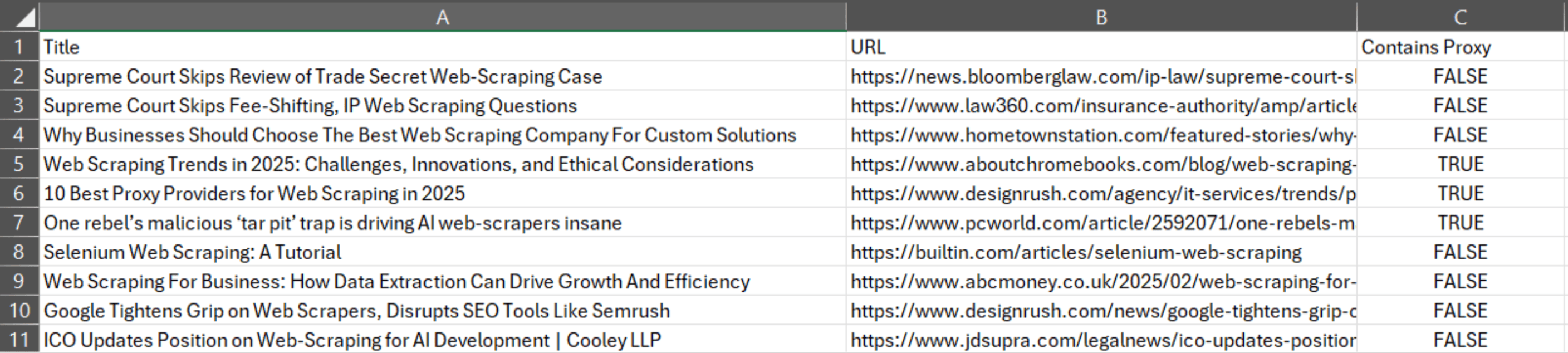
- Finds "proxy" or "proxies" phrases in the websites.
- Prints the title, URL, and whether the phrases were found.
- Prints the total number of mentions found and links scraped.
- Stores the data in a CSV file named
scraped_articles.csv - Closes the browser.
You should see the title, URL, and whether the phrases were printed in the terminal. As a final note, you can change the headless variable value to True to save resources and time, as graphically loading each website can be resource-intensive.
For a more in-depth tutorial on how to create your own Google News scraper with Python, read the full blog post.